What you should know about database storage and retrieval.
This post is a transcript of the talk I gave at Papers We Love @ Porto.
Log-Structured File
In 1991, Mendel Rosenblum and John K. Ousterhout introduced a new technique for disk storage management called log-structured file system.
A log-structured file system writes all modifications to disk sequentially
in a log-like structure, thereby speeding up both file writing and crash
recovery.

The idea of the log-structured file system is to collect large amounts of new data in a file cache in main memory, then write the data to disk in a single large I/0.
How do we avoid running out of space?

The log-structured system solution is to break the log into several immutable segments of a certain size by closing a segment file when it reaches a certain size, and making subsequent writes to a new segment file.
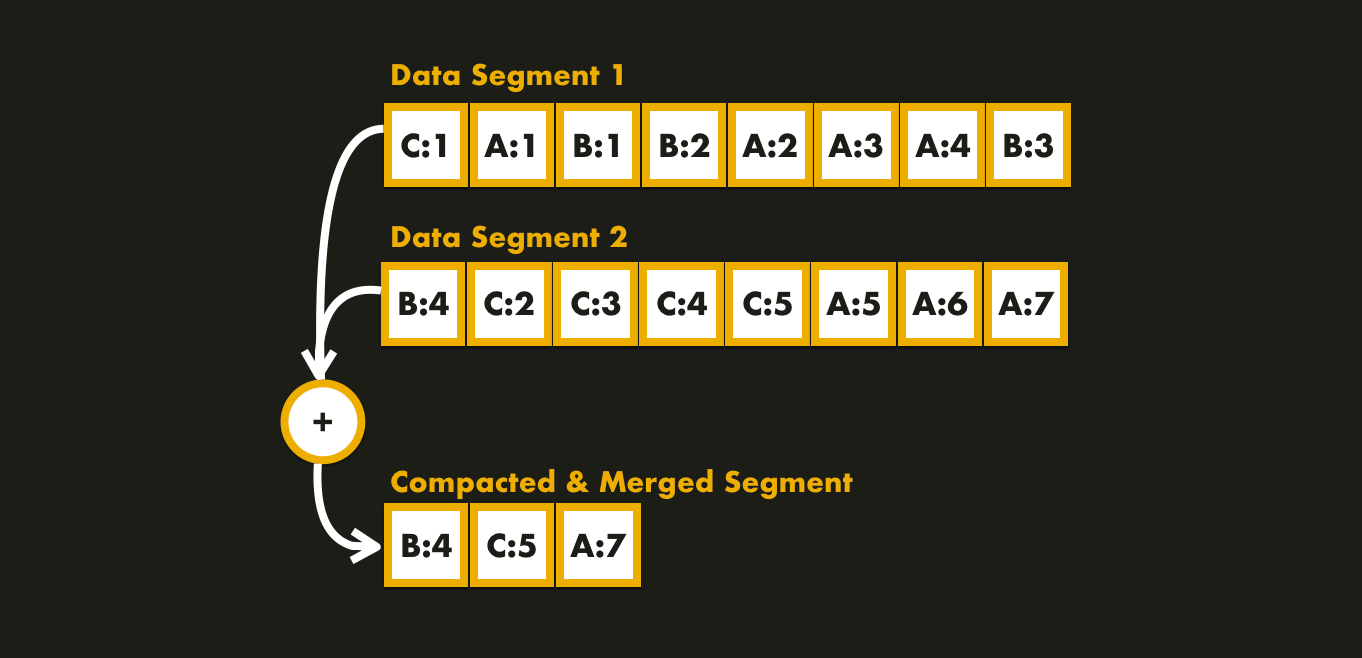
Since compactation makes segments much smaller, we can also merge several segments together at the same time as performing the compactation. This process can be done in a background thread while we can still serve read and write requests using the old segment files.
Why using an append-only log?
The immutable append-only design turns out to be good for several reasons!
- Sequential write operations are much faster than random writes;
- Concurrency and crash recovery are much simpler;
- Merging old segments avoids fragmentation over time.
How do we find the value of a given key?
The solution is to introduce an additional data structure that is derived from data: the index; the idea is to keep some additional metadata on the side that helps to locate the data. Although, maintaining such structures incurs overhead, especially on write!
Hash Indexes
The simplest possible indexing strategy is to keep an in-memory hash map where each key is mapped to a byte offset in the data file. The hash map is used to find the offset in the data file, seek to that location, and read the value.
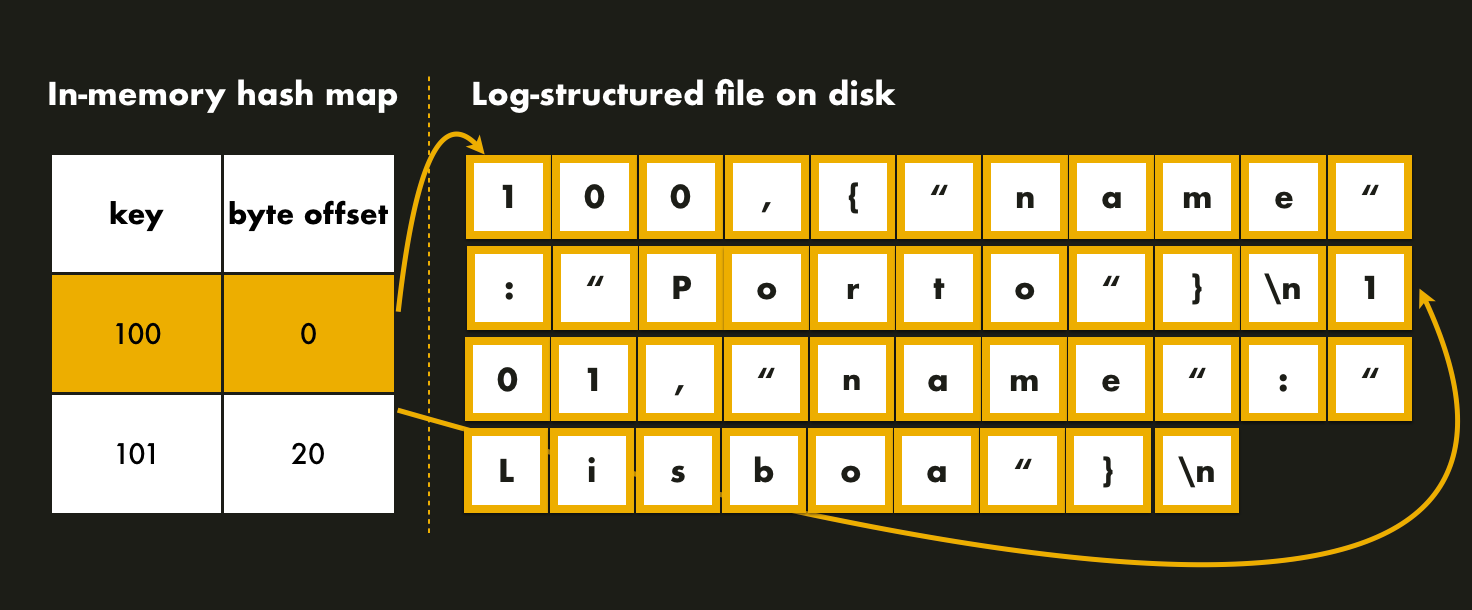
Note that the hash map is always updated when a new key-value pair is appended to the file in order to reflect the current data offset.
This solution may sound too simplistic, right? Actually, it is a viable approach. In 2010, Basho Technologies, a distributed systems company that developed a key-value NoSQL database technology, Riak, wrote a paper that introduced Bitcask, the default storage engine of Riak. Bitcask uses this concept of an in-memory hash map and offers high-performance reads and writes. The tradeoff is that all keys must fit in memory.

When a write occurs, the keydir is atomically updated with the location of
the newest data. The old data is still present on disk, but any new reads will
use the latest version available in the keydir.
Although, the in-memory hash map strategy has some limitations. As we saw from the Bitcask example, all keys must fit in the in-memory hash map, so this indexing strategy is not suitable for a very large number of keys and since the keys are not sorted, scanning over a range of keys it’s not efficient — it would be necessary to look up each key individually in the in-memory hash maps.
Sorted-String Tables
In 2006, Google wrote the Bigtable paper where introduced among other things, the SSTable - Sorted String Table; a sequence of key-value pairs that are sorted by key.

An SSTable provides a persistent, ordered immutable map from keys to values,
where both keys and values are arbitrary byte strings.
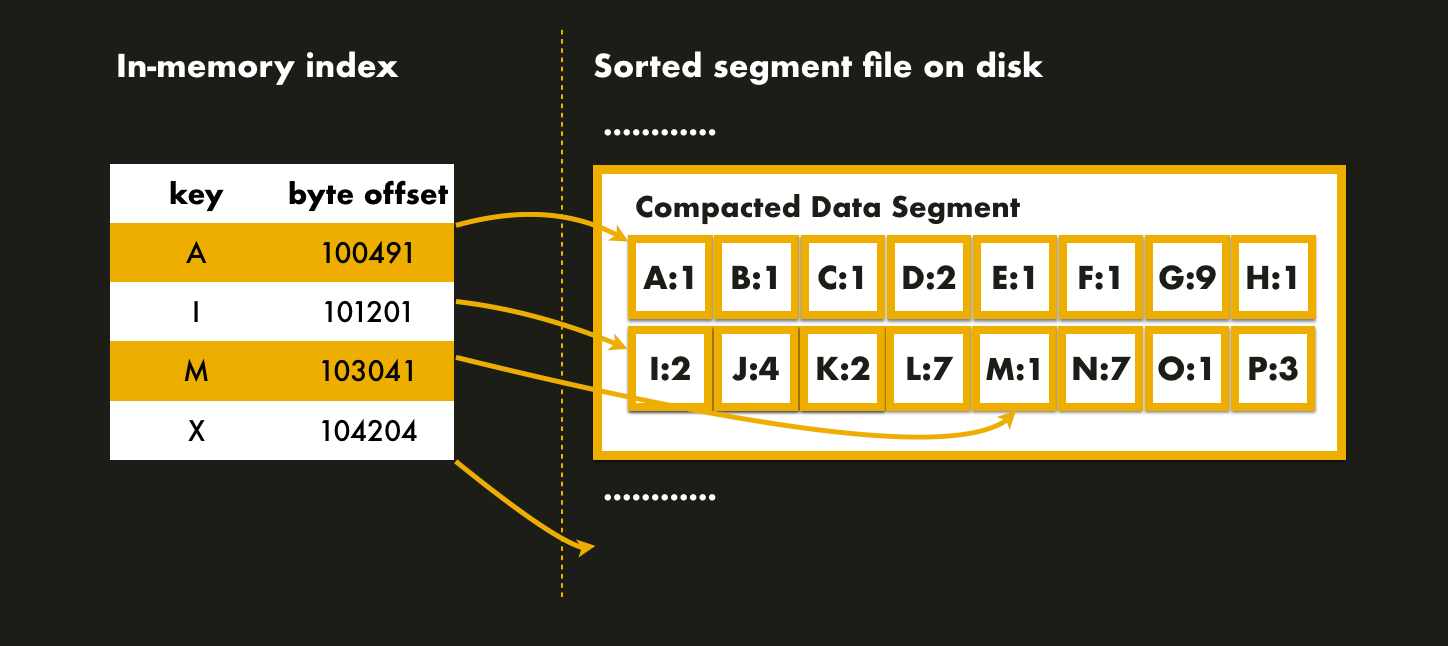
A lookup can be performed by first finding the appropriate block with a
binary search in the in-memory index, and then reading the appropriate block
from disk.
The recently committed records are stored in memory in a sorted buffer called a memtable. The memtable maintains the updates on a row-by-row basis, where each row is copy-on-write to maintain row-level consistency. Older updates are stored in a sequence of immutable SSTables.
As recently committed records are being stored in the memtable, it’s size increases and when the size reaches a threshold:
- the memtable is frozen;
- a new memtable is created;
- and the frozen memtable is converted to a SSTable and persisted on disk.
A lookup can be performed with a single disk seek by first finding the appropriate block by performing a binary search in the in-memory index and then reading the appropriate block from disk.
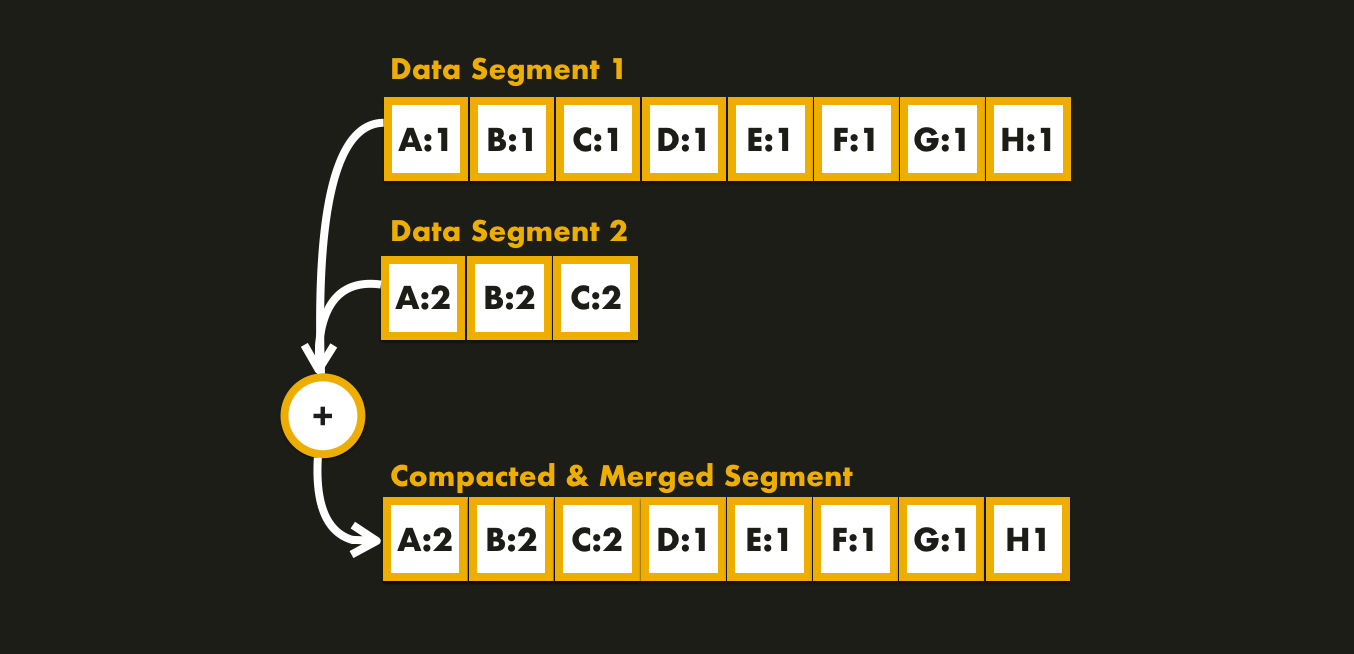
Since the segments are sorted by key, the merging approach is like the one used in the mergesort algorithm:
- we start reading the segment files side by side;
- look at the first key in each file;
- copy the lowest key to the new segment file;
- and repeat.
LSM-Tree
Storage engines that are based on this principle of merging and compacting sorted files are often called LSM storage engines. This concept was introduced in 2006 in The Log-Structured Merge-Tree paper; a disk-based data structure designed to provide low-cost indexing experiencing a high rate of record inserts over an extended period.

The LSM-tree uses an algorithm that defers and batches index changes, cascading
the changes from a memory-based component through one or more disk components in
an efficient manner reminiscent of merge sort.
What about performance?
The algorithm can be slow when looking for keys that do not exist in the database. Before we can make sure that the key does not exist, we first we need to check the memtable and the segments all the way back to the oldest. The solution is to introduce another data structure: the Bloom Filter - a memory-efficient data structure for approximating the contents of a set.
A Bloom filter allows us to ask whether an SSTable might contain any data
for a specified row/column pair. For certain applications, the small amount
of tablet server memory used for storing Bloom filters drastically reduces
the number of disk seeks required for read operations. Our use of Bloom
filters also avoids disk accesses formost lookups of non-existent rows
or columns.
Basically, the Bloom Filter can tell us if a key does not exist in the database, saving many unnecessary disk reads for non-existent keys. However, because the Bloom Filter is a probabilistic function, it can result in false positives.
B-Trees
In 1970, a paper on Organization and Maintenance of Large Ordered Indices, introduced the concept of B-Trees that less than 10 years have become, de facto, a standard for file organization. They still remain the standard index implementation in almost all relational databases, and many non relational databases use them too as well.

The index is organized in pages of a fixed size capable of holding up to
2k keys, but pages need only be partially filled.
Basically, B-trees break the database down into fixed-size pages, and read or write one page at a time!
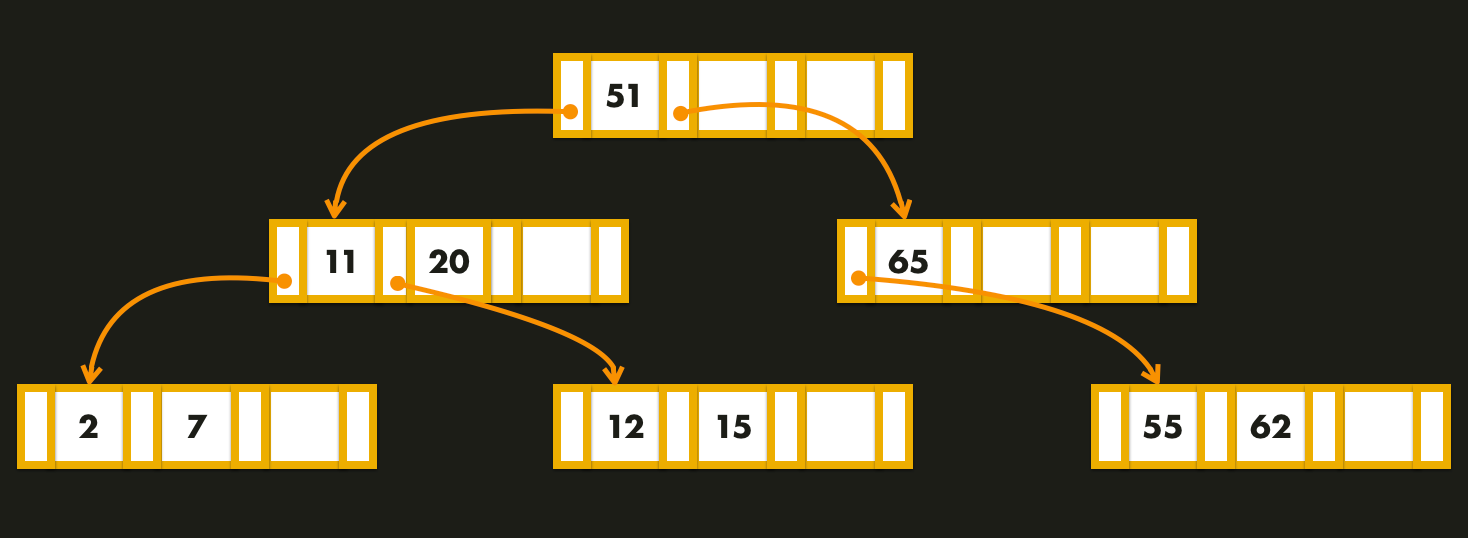
Each page can be identified using an address that allows one page to refer another page. One of those pages is designated as the root of the B-tree and whenever we want to look up a key in the index, we start from there and traverse the tree recursively down to the leaves.
The retrieval algorithm is simple logically, but to program it for a computer
one would use an efficient technique, e.g., a binary search, to scan a page.
In order to add a new key, we need to find the page within the key range and split into two pages if there’s no space to accommodate it. This is the only way in which the height of the tree can increase.
What about resilience?
If we need to split a page because an insertion caused it to be overfull, we need to write the two pages that were split, and also overwrite their parent page to update the references to the two child pages. Overwritten several pages at once it’s a dangerous operation that can result in a corrupted index if the database crashes.
The solution to tackle this problem is to introduce an additional structure - the Write-Ahead Log (WAL); where all modifications will be written before it can be applied to the tree itself. If the database crashes, the WAL will be used to restore the tree back to a consistent state.
But writing all modifications to the WAL introduces other problem - write amplification; when one write to the database results in multiple writes to disk which has a direct performance cost.
Wrapping up!
With this brief introduction on several types of data storage engines, we can take some conclusions:
- B-Trees are mutable and allow in-place updates;
- LSM-Trees are immutable and require complete file rewrites;
- Writes are slower on B-Trees since they must write every piece of data at least twice;
- Reads are slower on LSM-Trees since they have to check the memtable, bloom filter, and possibly multiple SSTables with different sizes;
- LSM-Trees are able to sustain higher write throughput due to lower write amplification and sequential writes, but they can consume lots of resources on merging and compaction processes, especially if the throughput is very high and it’s size is getting bigger.
What’s next?
There is no quick and easy rule for determining which type of storage engine
is better for your use case, so it is worth testing empirically.
You should read papers, and this list may help you with that: